
Architecting a Machine Learning System for Risk
Regarding the Twisto business model (which is similar to Swedish Klarna) we need to deal with considerable amount of risk that is embedded in customer portfolio and could materialize as loss or fraud. One of the core parts of our scoring mechanism thus is an application scoring tool which resembles risk tools used in most banks – but unlike banks we require only very little customer-provided information (No ID number or ID scan required etc.). Our aim is to provide fast and seamless shopping experience and we believe that customer assessment can be done without inconveniences like scanning an ID. The fewer demands we make on our customers the more demands we need to make on our risk tools because any imprecision leads to losing our money.
The post's title refers to an excellent and very instructive article written by Naseem Hakim and Aaron Keys from Airbnb in 2014. When we were dealing with task of designing a robust and flexible environment where our application scoring models could live, this article was our main source of inspiration.
Deployment
Our former scoring infrastructure included hardcoded logit models that worked well in general but had several serious drawbacks:
- The process itself put great demands on developer's capacity as "Deploying" new models meant to rewrite multiple rule-sets directly into Python, which was a very time consuming task
- It was possible to introduce serious bugs into scoring models during rewriting
- It wasn't possible to easily maintain multiple models at a time
- It wasn't possible to maintain multiple types of ML models (e.g. Logit and Random Forests)
As we are using Python as the "language of choice" to develop most of our infrastructure, betting on well known Python library called scikit-learn was a sure shot.
Scikit-Learn and Model Persistence
Although scikit-learn is a top quality library containing state-of-the-art algorithms for ML it doesn't allow much when it comes to deal with model persistence – even does not have such ambitions.
Literature is not going much deeper. Most of the time it is explaining pickle based solutions. To be honest such approach may be enough for examples in books, tutorials, etc. but definitely it's not robust enough for production level services. See detail explanation in excelent talk Pickles are for Delis, not Software by Alex Gaynor @ PyCon 2014 (Talk on youtube).
We could imagine a custom persistence solution based on SQL or non-SQL databases or even a text-based (JSON/XML) representation of our models but we were wondering whether there is a solution that would suit our needs – so we avoid reinventing the wheel. After reading the mentioned article from Airbnb we had the impression that PMML and Openscoring might be a good way to go.
Stack Overview
PMML
The Predictive Model Markup Language (PMML) is XML-based file format developed by the Data Mining Group to provide a way for applications to describe and exchange models produced by data mining and machine learning algorithms.
Sklearn2pmml
Is a Python library that provides a way how to persist a trained scikit-learn model into PMML.
Openscoring
Is RESTful web service that manage and interpret predictive models represented by PMML. Exposing predictive models through REST service is an elegant way how to provide interoperability and scalability of scoring engine.
Infrastructure Overview
Unlike guys at Airbnb we have no separate service for feature extraction – we deal with this task using asynchronous tasks via Celery/Redis. To get a better picture see following image:
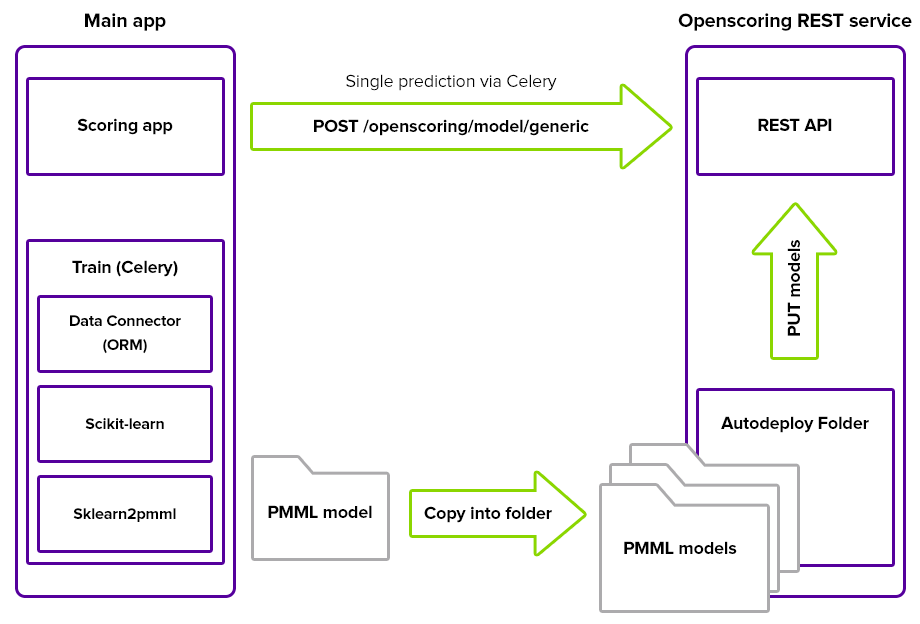
Because Openscoring doesn't maintain deployed models after server restart – there are two approaches of how to deal with this:
- It may be possible to upload models into autodeploy folder which is then chosen during Openscoring server starts as argument.
- Generated models are deployed using
HTTP PUTto the proper endpoint from some file repository
Conclusion
Few words to summarize – suggested architecture allows us to separate responsibilities of our Risk and Development teams. It's easy now to get new ideas into production fast as it takes minimum effort to be deployed. We are now able to fully automate our development / deployment process and thus react on changing patterns in fraudster's behavior.
On the other hand PMML is not "the Holy Grail" to solve all the problems – for example it is not able to cover all thinkable types of prediction models and/or all thinkable preprocessing tasks. As every standard it's just the greatest common divisor of the particular domain, but for us it is fair enough tradeoff to cover most of our requirements. It needs to be said that described architecture is related only to application scoring which is just a part of the complex engine (meet Nikita) that allows us to effectively deal with risk.
We'll be happy to hear your opinions, experience, etc. about prediction model deployment phase.
- Václav Čadek, Data Scientist at Twisto